LLMGraphTransformer는 텍스트를 Neo4j에 저장할 수 있는 지식 그래프 형태로 변환하는 LangChain 라이브러리입니다.
• 비슷한 성질의 텍스트 리스트를 입력하면, 해당 요소들의 관계를 추출하여 노드와 엣지(관계)를 자동 생성합니다.
• 노드와 엣지를 LLM이 판단하여 자동 생성하는 것이 주요 장점입니다.
• 그래프의 Retrieval 기능을 추가하면 GraphRAG 방식으로 활용 가능합니다.
최근에는 비정형 데이터로부터 KG(Knowledge Graph)를 구축하는 파이프라인을 만드는 중입니다.
현재는 LLMGraphTransformer와 같은 패키지가 데모용으로 많이 쓰이는 듯합니다.
하지만 제가 궁극적으로 원하는 형태로 만들기 위해 LLMGraphTransformer는 명확한 한계가 존재합니다.
디테일하게 파라미터를 조정할 수 가 없기 때문에 Knowledge Graph 구축에 많은 제한이 걸립니다.
오늘은 그 3가지 이유에 대해서 말을 해볼 것입니다.
1 .T2K를 하기 위해선 각각의 도메인에 맞는 구조가 무엇인지 알고 Entity를 추출해야한다.
Text to Knowledge Graph란 말 그대로 글로부터 지식 그래프를 만드는 것입니다.
그런데, 사람이 지식 체계를 구축할 때 사전 지식이 있는 사람과 없는 사람에게 똑같은 글을 준다면 어떤 사람이 더 좋은 지식의 형태를 갖출까요? 아무래도 사전 지식이 있는 사람이 훨씬 유리할 것입니다.
그 이유를 더 깊게 파고들자면 지식은 관계와 Key - Value로 정의되고 이 정의로부터 새로운 관계와 Key - Value가 정의될 것 입니다.
하지만 사전지식이 있는 사람은 어떤 글을 보았을 때 전후사정을 파악하여 그 글에 대한 이해가 더 빠르고 무엇이 정확한지 유추해낼 수 있습니다. 그렇기 때문에 Text to Knowledge graph도 마찬가지로 그 글에 대한 도메인 사전지식이 있어야 더욱 나은 Relationship을 정의하고 그로부터 나오는 Relation Path Reasoning을 할 수 있을 것입니다.
마치 삼단 논법의 개념과도 비슷합니다.
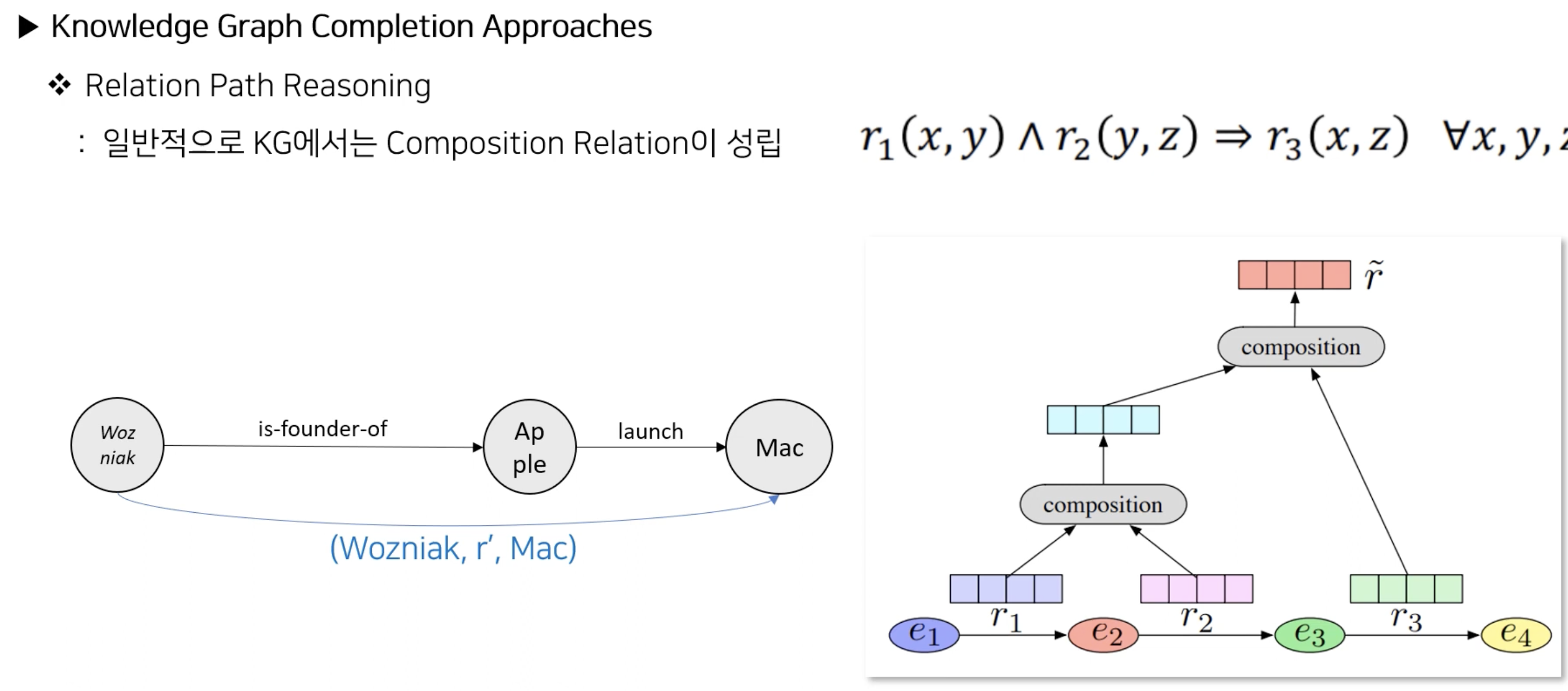
그림 출처: 서울대학교 DSBA 연구실 유튜브 https://youtu.be/_THQzPiLvyI?si=MWsIHCM10tpQIvUF
2. Entity 중복 검출 방지
Location'과 'Place', 'Literary_work'와 'Book'처럼 동의어로 간주되는 타입을 병합하는 정규화(canonicalization) 과정도 일관성을 높이고 중복을 줄여야합니다.
LLM 특성상 항상 일관된 답변을 내놓지 않으므로 같은 뜻이지만 다른 Entity와 연결 될 수 있습니다.
이는 잘못된 지식그래프 구축으로 가게되는 원인이 될 가능성이 큽니다.
따라서, 이를 방지할 솔루션을 도입해야합니다.

3 .그래프가 구축되기 위한 기준이 적고 모호함
그래프는 굉장히 유연하기 때문에 다양한 구조를 뛸 수 있습니다.
그렇기 때문에 초기에 어떤 기준으로 어떻게 관계를 맺고 앞으로 뻗어나갈 것인지 명확한 기준과 설계가 필요합니다.
이런 부분에 있어서는 연구와 함께 최적의 아키텍처를 찾아야할 것 입니다.
'AI 오픈소스 리뷰(Open source review)' 카테고리의 다른 글
| [HybridAGI ] Agent의 행동을 그래프 기반으로 최적화할 수 있는 오픈소스 (6) | 2025.01.19 |
|---|